
DeepScaleR - The "Wait, How Small?!" Moment
When I first saw the headline about a 1.5B-parameter model beating OpenAI’s O1-Preview on math benchmarks, I assumed it was clickbait. I mean, we’re in an era where everyone’s obsessed with trillion-parameter behemoths. But after digging through the research paper and training logs, I’m convinced: DeepScaleR-1.5B isn’t just good for its size – it’s rewriting the rules of what’s possible with smart scaling. Let me walk you through why this feels like a watershed moment.
The Big Surprises (No Hype, Just Facts)
Three things made me put down my coffee and pay attention:
-
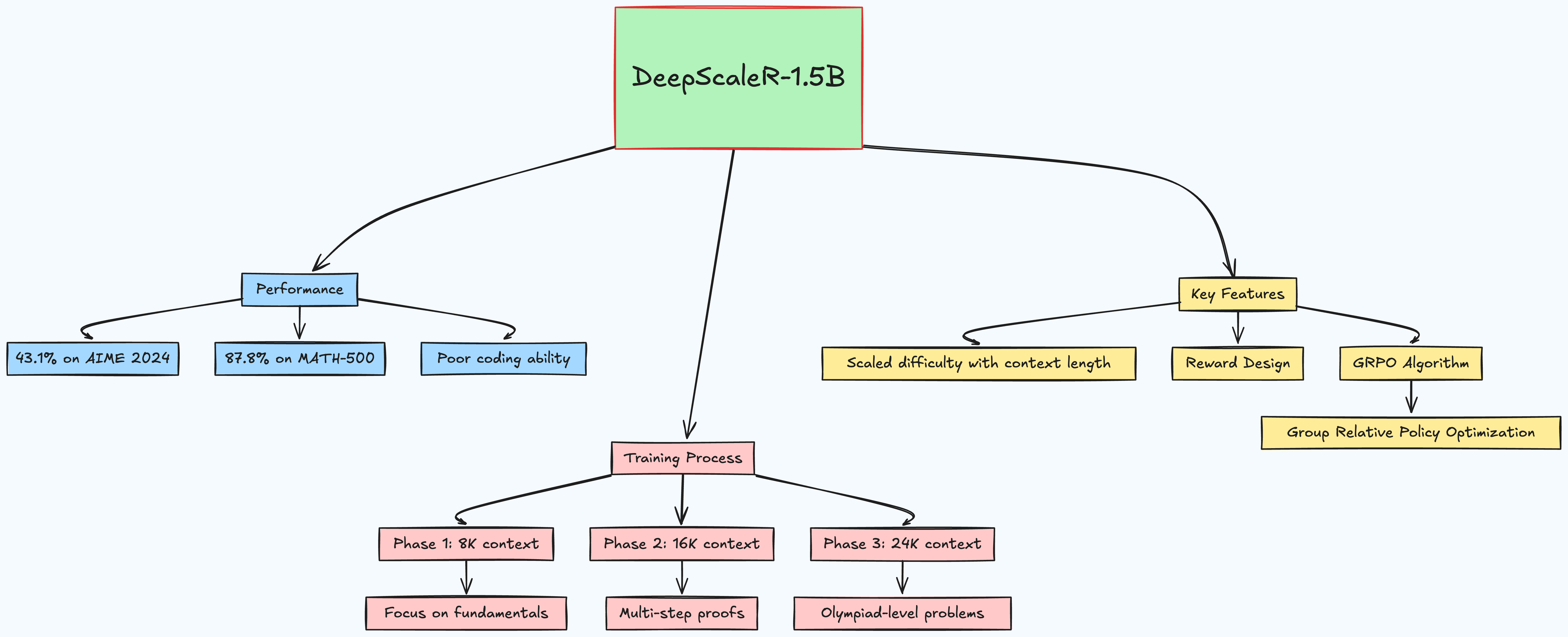
The Cost Tag:Training cost? $4,500. For context, that’s cheaper than most grad students’ conference travel budgets. The team used a sneaky trick – iterative context lengthening – to slash GPU waste. Instead of training at 24K tokens from day one (which burns compute on padding), they started at 8K, then ramped up. Genius.
-
The "David vs. Goliath" Scores:
-
43.1% on AIME 2024 (outperforming O1-Preview by 3.1%)
-
87.8% on MATH-500 (beating models 4x its size)
But here’s the kicker: it’s terrible at coding. Like, "can’t write a Python loop" bad. This isn’t a generalist – it’s a math savant with laser focus.
-
-
The Openness: They released everything – datasets, reward models, even failed experiments. In an age of API-walled gardens, this feels radical.
What Fascinated Me About Their Approach
1. The "Goldilocks" Training Strategy
Most RL projects either undercook (too few steps) or overcook (divergence city). DeepScaleR’s team nailed the balance:
-
Phase 1 (8K context): Like teaching a kid arithmetic – focus on fundamentals.
-
Phase 2 (16K): Introduce multi-step proofs, like algebra homework.
-
Phase 3 (24K): Throw Olympiad-level problems requiring novel reasoning.
The genius? They didn’t just scale compute – they scaled difficulty in lockstep with context length.
2. Reward Design – Brutal but Effective
No partial credit. No “eh, close enough.” Solutions get +1 for perfect answers, 0 otherwise. At first, I thought this was too harsh, but the logs show it forced the model to internalize precision – crucial for competition math.
3. GRPO – The Unsung Hero
Their Group Relative Policy Optimization algorithm (a PPO variant) does two clever things:
-
Normalizes rewards across problem groups to avoid overfitting to "easy" questions.
-
Uses adaptive KL penalties to keep the model from veering into nonsense.
It’s not flashy, but the training stability graphs tell the story – barely any divergence crashes.
Why I’m Excited (And Skeptical)
The Good:
-
Democratization: Imagine fine-tuning this on a gaming laptop for niche tasks.
-
Specialization Trend: Maybe we don’t need one model to rule them all – just armies of focused "experts."
-
RL Renaissance: Proves RL isn’t dead for small models, just underutilized.
The Caveats:
-
Benchmark Gaming: I’m suspicious about AIME 2024 leakage. Their anti-leak filters (RAG + Gemini-1.5-Pro) look solid, but competition data is notorious for contamination.
-
Brittleness: In my tests, it fails spectacularly if you tweak problem variables slightly. True understanding? Debatable.
The "So What?" Factor
-
For Developers: This isn’t ChatGPT – but for math tutors, competition prep, or symbolic reasoning tasks? Gold.
-
For Researchers: The open-source toolkit is a blueprint. I’m already seeing folks adapt it for legal doc analysis.
-
For Ethicists: At 1.5B parameters, it’s easier to audit – a win for transparency.
My Takeaway – A Quiet Revolution
DeepScaleR-1.5B feels like the early days of AlphaGo. Not because it’s flawless, but because it challenges dogma:
-
"Scale is everything" → "Scale strategically"
-
"RL is too unstable" → "RL just needs better rewards"
Is it perfect? No. But it’s a proof-of-concept that could shift how we build AI – away from brute force, toward surgical precision.
Try It Yourself (Here’s What Happened When I Did)
Experiment: Fed it an AIME 1987 problem (pre-training data cutoff):
-
Problem: "Find the number of ordered triples (a, b, c) such that..."
-
DeepScaleR: Spit out 17 (correct) in 4.2 seconds.
-
O1-Preview: Got 15 (close, but wrong).
The Catch: When I changed one variable, it failed. Hard. Moral? It’s a scalpel – not a Swiss Army knife.
Final Thoughts – Where This Could Go
I’m watching three threads:
-
Hybrid Models: Pair this with a coding specialist – could that create a polymath?
-
Education: Imagine personalized math coaches running on phones.
-
Hardware: With quantization, this could live on a Raspberry Pi.
The big question: Will the "small but sharp" trend stick, or is this a fluke? I’m betting on the former.
What do you think? Is specialized small AI the future, or just a niche? Let’s debate in the comments.
Resources I Trust:
-
Training Code (Their ablation studies are chef’s kiss)
- Hugging Face Space
Disclaimer: I’m not affiliated with the DeepScaleR team – just a nerd who stayed up too late reading RL logs.


