
1. Introduction to GRPO
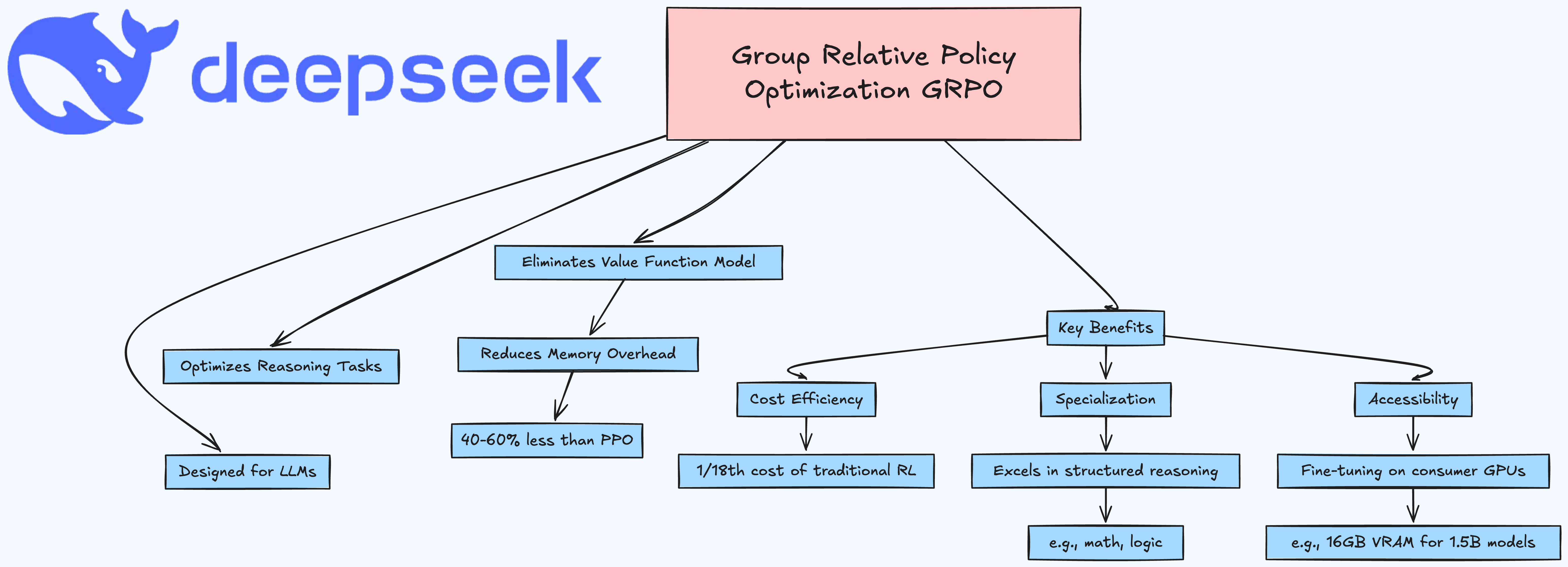
Group Relative Policy Optimization (GRPO) is a reinforcement learning (RL) algorithm designed to optimize large language models (LLMs) for reasoning tasks. Introduced in the DeepSeekMath and DeepSeek-R1 papers, GRPO eliminates the need for a value function model, reducing memory overhead by 40-60% compared to Proximal Policy Optimization (PPO).
Why GRPO Matters
-
Cost Efficiency: Trains models at 1/18th the cost of traditional RL methods.
-
Specialization: Excels in tasks requiring structured reasoning (e.g., math, logic).
-
Accessibility: Enables fine-tuning on consumer GPUs (e.g., 16GB VRAM for 1.5B models).
2. GRPO vs. PPO: Key Innovations
Feature |
PPO |
GRPO |
|---|---|---|
Value Model |
Required |
Eliminated |
Advantage Calc |
Single response per prompt |
Group-based normalization |
KL Divergence |
Optional regularization |
Integrated into loss function |
Memory Usage |
High (4 models in pipeline) |
Reduced by 50% |
Key Innovations:
-
Group Sampling: Generates multiple responses per prompt (e.g., 4–8) and normalizes rewards within the group .
-
KL-Penalized Updates: Prevents policy drift using KL divergence from a reference model (e.g., SFT baseline) .
-
Simplified Architecture: Removes the value model, relying on reward means/stds for advantage estimation .
3. Mathematical Foundations
GRPO Objective Function
The loss combines clipped policy gradients and KL penalties:
LGRPO=−1G∑i=1G[min(πθπoldAi,clip(πθπold,1−ϵ,1+ϵ)Ai)]+β⋅DKL(πθ∣∣πref)
-
G: Group size (e.g., 4 responses per prompt) . -
ϵ: Clipping range (typically 0.15–0.3) . -
β: KL penalty weight (e.g., 0.0005) .
Advantage Calculation
Advantages are normalized within each group:
Ai=ri−μrσr+1e−8
where μr and σr are the mean and standard deviation of group rewards .
4. Step-by-Step Implementation Guide
GRPO example - A Study Group (With Pizza! 🍕)
Imagine you’re in a study group with 5 friends, all solving the same math problem:
Problem: "If 3 pizzas cost $30, how much does 1 pizza cost?"
Each friend writes their answer differently:
-
Alex: "30 ÷ 3 = 10. So $10." (Correct!)
-
Bella: "3 × 10 = 30. So $10." (Correct, different approach!)
-
Chris: "30 − 3 = 27. So $27." (Wrong!)
-
Dana: "30 ÷ 3 = 12." (Mistake in division!)
-
Eli: "3 + 30 = 33." (Totally off!)
How GRPO Works (The Smart Teacher’s Trick)
Instead of just saying "Alex is right, others are wrong," GRPO does something clever:
-
Step 1: Compare All Answers
-
The group’s average answer is:
-
Correct answers (10,10) → Good!
-
Wrong answers (27,12, $33) → Bad!
-
-
The baseline is around $18.4 (average of all answers).
-
-
Step 2: Reward/Penalize Based on Group Performance
-
Alex & Bella get +1 point (since they’re above average).
-
Chris, Dana, Eli get -1 point (below average).
-
-
Step 3: Learn from the Best
-
The AI adjusts its thinking to favor steps like Alex’s and Bella’s.
-
Next time, it’s more likely to divide correctly and less likely to guess randomly.
-
Why This Beats Old Methods (PPO = One Strict Teacher)
-
Old Way (PPO): A single teacher checks each answer and says "Right/Wrong."
-
Slow, needs extra work (like a "critic model").
-
-
GRPO Way: The group grades itself—no strict teacher needed!
-
Faster, uses less memory, and learns from multiple perspectives.
-
Real AI Example: Solving 2x + 4 = 10
Suppose the AI generates 3 solutions:
-
Solution A:
-
Step 1:
10 − 4 = 6✅ -
Step 2:
6 ÷ 2 = 3✅ -
Final Answer:
x = 3
-
-
Solution B:
-
Step 1:
10 ÷ 2 = 5❌ -
Step 2:
5 − 4 = 1❌ -
Final Answer:
x = 1
-
-
Solution C:
-
Step 1:
4 − 10 = -6❌ -
Step 2:
-6 × 2 = -12❌ -
Final Answer:
x = -12
-
GRPO’s Move:
-
Rewards Solution A (since it’s the only correct one).
-
Penalizes B & C (but notices B was closer than C).
-
Next time, the AI will prefer steps like Solution A.
GRPO is like a study group voting on the best method—no single "teacher" needed! This makes AI:
✅ Faster (no extra "critic" model).
✅ Smarter (learns from relative success, not just right/wrong).
✅ More efficient (works great even with small training data).
Try It Yourself!
Next time you solve a problem, think: "How would a study group of AIs grade my steps?" 🚀
Prerequisites
-
Python 3.10+, PyTorch 2.2+, Hugging Face
trllibrary. -
GPU with ≥16GB VRAM (e.g., NVIDIA A100, RTX 4090).
Workflow
-
Supervised Fine-Tuning (SFT): Train a base model on high-quality demonstrations.
-
Reward Modeling: Define task-specific rewards (e.g., correctness, formatting).
-
GRPO Training: Optimize policy using group-based RL.
5. Advanced Techniques
Optimizing VRAM Usage
-
Use 4-bit quantization with
bitsandbytes. -
Enable vLLM for faster generation:
training_args = GRPOConfig(..., use_vllm=True)Hyperparameter Tuning
| Parameter | Recommended Range | Effect |
|---|---|---|
Group size (G) |
4–8 | Higher → Better baseline estimate |
KL weight (β) |
0.0001–0.001 | Higher → Less policy drift |
Clipping (ε) |
0.1–0.3 | Higher → More conservative updates |
7. Case Study: DeepSeek-R1
DeepSeek-R1 achieved 51.7% accuracy on the MATH benchmark using GRPO, outperforming GPT-4 on cost-adjusted metrics 7. Key lessons:
-
Iterative Training: Alternate between SFT and GRPO phases .
-
Synthetic Data: Generate 800k examples with LLM-as-a-judge filtering .
-
Reward Design: Combine correctness, formatting, and consistency rewards.
Conclusion
GRPO democratizes RL training for LLMs, enabling researchers to build specialized models on consumer hardware. While challenges remain (e.g., reward hacking, overfitting), its efficiency and open-source tooling (e.g., TRL, Unsloth) make it a cornerstone of modern AI development.
Resources:


